
The tech world has a favorite essay. Walk into any AI strategy meeting, and someone will inevitably reference Rich Sutton’s “The Bitter Lesson” to justify why they need more compute, more data, more hands. It’s become the go-to intellectual cover for brute-force approaches to AI, a sophisticated way of saying “just throw more resources at it.”
But here’s what separates serious AI practitioners from the pseudo-intellectuals:
Understanding that Sutton wrote another, equally important essay called “Verification”. If a person only quotes the Bitter Lesson essay without acknowledging the Verification essay, you’re likely dealing with someone who hasn’t fully grokked what’s actually required to deploy AI successfully in the real world.
The Real Bottleneck Isn’t What You Think
Something that most don’t want to say out loud:
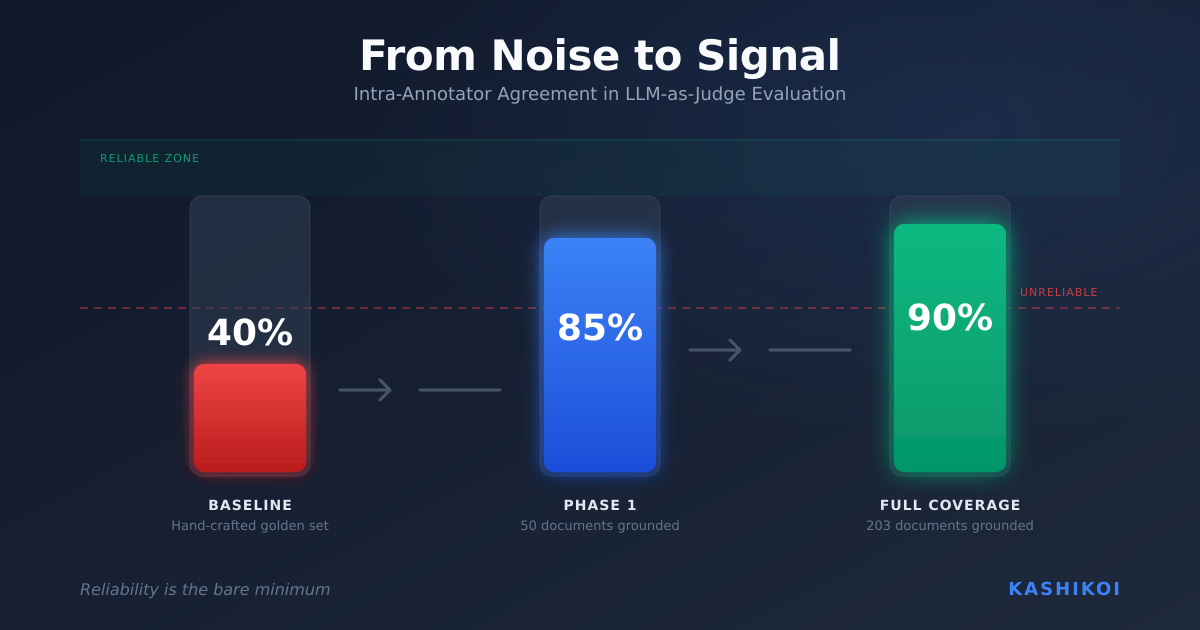
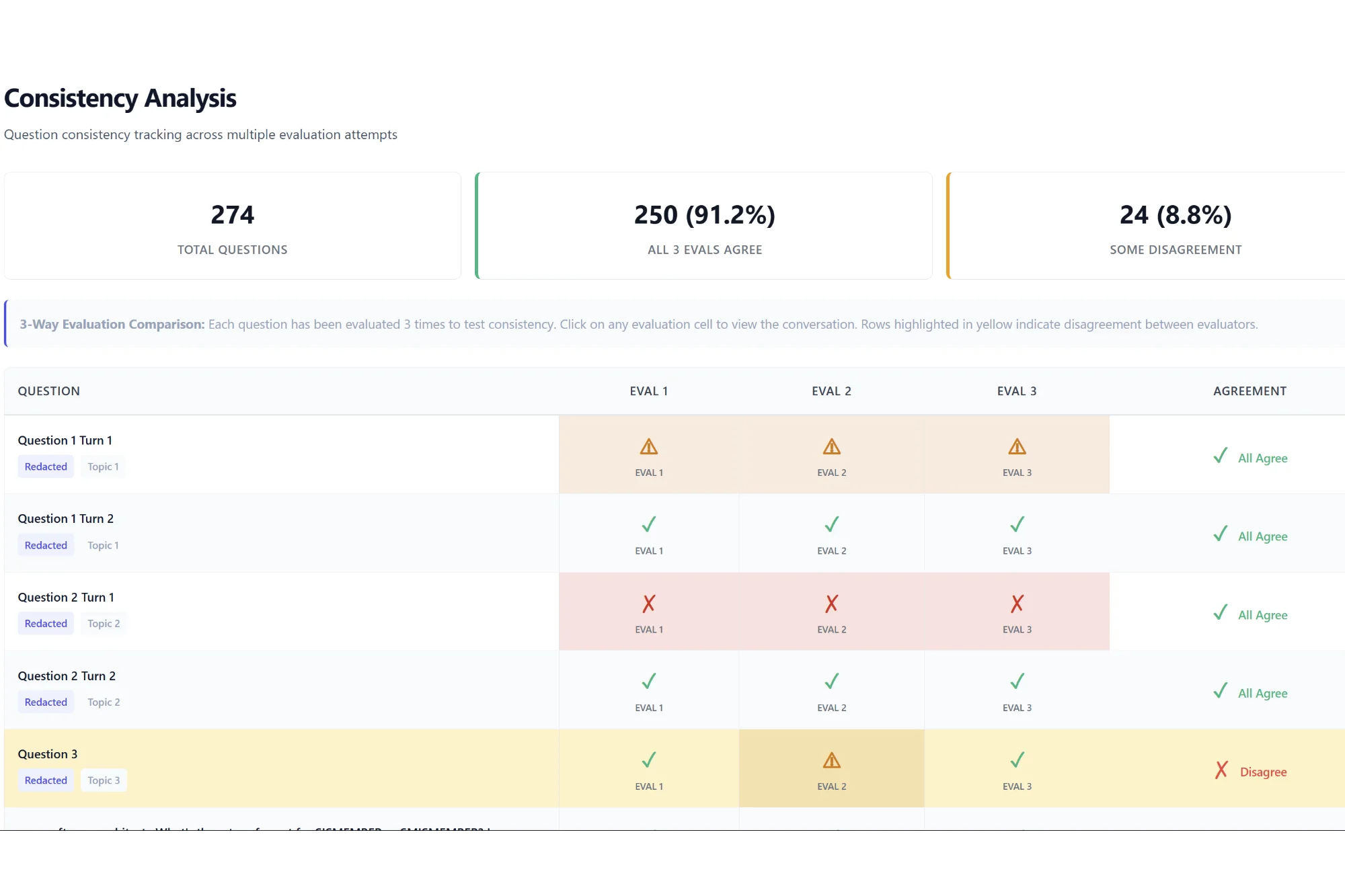
We are no longer limited by an LLM’s ability to consume and generate. We are now limited by our ability to review and verify what LLMs are generating.
This fundamental challenge faces every enterprise trying to deploy AI at scale. While the industry has converged on “LLM-as-Judge” as a stopgap solution, this approach won’t solve the underlying problem. The real answer lies in using environments and simulation to verify agents. This same paradigm has already enabled some of the most successful autonomous deployments affecting our physical world.
Learning from Real-World Autonomous Systems
While we struggle with prompt engineering and agent architectures, neural network-based systems are already delivering massive efficiency gains in high-stakes physical environments. Let’s look at three groundbreaking examples:
| Domain | What the Autonomous System controls | Real-world Payoff |
|---|---|---|
| Data-center cooling (Google, Meta) | Fan speeds, chiller set-points, pump flow rates | Cut cooling energy use by up to 40 % and total facility power by ~15 %. Google lets the agent act directly, while a human operator watches the safety constraints. (deepmind.google, wired.com, engineering.fb.com) |
| Nuclear-fusion plasma (EPFL TCV tokamak) | Currents in 19 magnetic coils every millisecond | Maintains complex X-point and “snowflake” plasmas for seconds and even creates shapes no human expert has tried before—an essential step toward steady-state fusion. (nature.com, deepmind.google) |
| Chip floor-planning (Google TPUs) | Placement order of ~10,000 blocks on silicon | Produces production-ready layouts in <6 h that match or beat senior engineers on power, performance, and area; the method has shipped in several TPU generations. (nature.com, wired.com) |
The Common Patterns
What made these deployments successful? Four critical patterns:
1. High-Stakes, High-Dimensional Control These systems juggle thousands of interacting variables in real-time, something rule-based controllers can’t handle.
2. Sample-Efficient Training None of these agents learned by “just trying things” in production. They relied on simulators, offline logs, and domain randomization before being fine-tuned on-site.
3. Human-Plus-AI Workflows The RL policy handles microsecond control; humans set goals and safety constraints.
4. Generalization Beyond Training These systems demonstrated transferable learning. For example, the tokamak controller created entirely novel plasma configurations.
The Critical Insight: Where Human Expertise Actually Matters
Here’s where the Bitter Lesson gets interesting. While these successful deployments used general-purpose learning methods (neural networks), human expertise wasn’t eliminated. Instead, it was relocated. Domain experts invested their knowledge into:
- High-fidelity simulators that accurately model the problem space
- Reward engineering that encodes what success actually looks like
- Safety constraints that prevent catastrophic failures
The neural networks themselves remain uninterpretable black boxes. But by embedding human knowledge into the verification and simulation layer, we achieve both the scalability of learned systems and the reliability enterprises require.
| Real-world deployment | Core simulator / toolkit | What it models |
| Data-centre cooling (Meta) | Physics-based building-energy model (custom, similar to DOE-2/EnergyPlus) | Air-flow, heat, humidity, fan power, water usage |
| Tokamak plasma control (Google DeepMind + EPFL) | High-fidelity magnetic-equilibrium codes (EFIT/SPIDER) + fast differentiable transport model TORAX written in JAX | Full plasma current-density evolution and coil circuit dynamics at ~10 kHz |
| Chip floor-planning (AlphaChip / “Circuit Training”) | C++ cost binary PLC wrapper + DREAMPlace placer + net-list protobuf | Wire-length, congestion, density in sub-10 nm blocks |
From Physical Systems to LLM Agents
This brings us to today’s challenge with LLM-based agents. There is no perfect prompt. There is no perfect agent architecture. But there exists a prompt and architecture that will get you in the ballpark, and that’s what matters.
We need to leave the confines of deterministic unit tests and enter a world of probability distributions. The question becomes “Is the likelihood of success high enough for my use case?” rather than demanding perfection every time. This requires robust evaluation systems backed by diverse sample sets. Think of it as good old statistics, reimagined for the age of AI.
The Playbook for Enterprise AI
As we move toward increasingly autonomous systems, our efforts are best utilized in building verification systems and high-fidelity simulators that align models to our definition of utility and intelligence. This approach provides the scalable way to overcome our current limitation: our inability to review and verify AI outputs at the pace they’re generated.
The playbook is clear:
- Invest in definitions of effective metrics, criteria, and evaluations
- Build simulation as the scalable way to align prompts, agent architectures and models
- Leverage domain expertise in the verification layer, not the policy itself
- Design reward systems that encode your actual business objectives.
To be precise, here’s how this playbook stacks up against the warnings in the Bitter Lesson:
| Aspect | Bitter Lesson view | Actionable Playbook Step |
|---|---|---|
| Reward & Constraints | Fine: they specify what we want, not how to achieve it. | Invest in definitions of effective metrics, criteria and evaluations |
| High-fidelity Simulator | Fine: it generates data so general methods can learn—it is not part of the deployed policy. | Simulation is the scalable way to align prompts, agent architectures and models. |
| Hand-tuned features or decision rules inside the NN | Fails the lesson; | Domain expertise should be invested as much as possible upstream when designing an autonomous system. |
Building the Future at Kashikoi
At Kashikoi, we’re making this playbook accessible to every enterprise. We’re building the simulation and evaluation infrastructure that will enable the next generation of reliable, high-impact AI deployments.
The companies that win in the AI era won’t be those with the most compute or data. They’ll be those who master the art of verification through simulation. The Bitter Lesson is only half the story. The sweet victory comes from knowing where to apply human insight in the age of autonomous systems.
Stay tuned for exciting announcements about our enterprise collaborations and product releases. The future of verified AI is closer than you think.
Want to learn more about building robust AI systems for your enterprise? Contact us at founders [at] getkashikoi.com to discuss how simulation and verification can unlock AI’s potential for your organization.

Leave a Reply