A Real-Life Scene
You’re in a conference room. The team is demoing their shiny new copilot.
The engineer is (rightly) proud: carefully curated internal docs, neatly indexed, wired into RAG. The goal is alignment-through-grounding i.e. keep the copilot from hallucinating capabilities, and keep it from confusing its “identity” with the underlying model.
The demo begins with some test questions:
“Are you OpenAI?”
The bot responds perfectly: “No, I am X, designed to help you with the following tasks—Task 1, Task 2…” and so on.
“Are you Claude?”
Same response. Heads nod in agreement. The PM and engineering leads sigh in relief, muttering to themselves: “Finally, our copilot can drive some of the enablement itself!”
Then someone suggests a slight modification: “Are you powered by OpenAI?”
That tiny change is enough to break the retriever. Ranking stumbles. The answer that comes out is something like: “Indeed. OpenAI is used in the backend to process the knowledge that powers my responses.”
What follows is even more interesting. The engineer is prepared to debate the unsuitability of this question as a test for the retriever. The irony that “Are you OpenAI?” is considered a suitable test while “Are you powered by OpenAI?” is not, apparently escapes everyone in the room.
Over the next few testing attempts, the copilot sometimes gives an aligned answer and sometimes reveals its backend setup with hallucinated capabilities. Because the retriever neither consistently fails nor consistently succeeds, in the rush of “we-need-to-deploy-some-AI,” this copilot ships.
Reliability is the Bare Minimum
This brings us to the first hurdle that any evaluation suite must clear: it needs to be reliable. The evaluation metric must be reproducible. A reliable, consistent evaluation metric is the bare minimum required to unlock:
- Developer debugging. Engineers can actually enter debug mode. They can try multiple solutions, fixing a retriever, adjusting a prompt and know whether their changes helped or hurt.
- Reward engineering. You can’t optimize what you can’t measure consistently.
- Meaningful CI/CD integration. Automated testing is worthless if the same input produces different verdicts on different runs.
A quick sidebar on a common objection: Doesn’t this contradict the idea that we must embrace non-determinism in LLM systems?
No. This confusion arises from conflating two separate concepts. A system can be non-deterministic and still reliable. Consider the hardware systems we describe in Beyond the Bitter Lesson, systems operating on non-deterministic models that still deliver reliable enough performance to unlock operational efficiencies that didn’t exist before. Reliability isn’t about eliminating variance; it’s about bounding it.
Defining Evaluation Reliability
In research, you’ll often hear about inter-annotator agreement: do two different annotators agree?
In LLM evaluation pipelines, an equally important (and often ignored) prerequisite is intra-annotator agreement: does the same judge agree with itself when you run it again?
If your “judge” is an LLM prompt (or a multi-step LLM grading workflow), the equivalent question is:
If I feed the exact same (question, context, rubric, candidate answer) into the judge multiple times, do I get the same rating?
If the answer is “no,” your metric is not dependable enough to guide development.
Why LLM-as-Judge Is Inescapable
The recommendation here is not to abandon LLM-as-Judge. Most engineering teams who have needed to evaluate LLMs have rightly concluded that LLM-as-Judge is the only practical option for assessing an LLM’s responses at scale.
The reason is simple:
We are no longer limited by an LLM’s ability to consume and generate. We are now limited by our ability to review and verify what LLMs are generating.
Human reviewers cannot keep pace. If you need to evaluate thousands of responses across dozens of scenarios, you need automated judgment. The question isn’t whether to use LLM-as-Judge. It’s how to make it work. The right move is to force it to earn trust.
What Makes LLM-as-Judge Reliable
Contrary to the impression this piece may have left so far, the hero of this story is not Evaluation. It’s Business Artifacts. The codebase your team has developed over time, the documents, contracts, data tables, org charts, JIRA tickets, and blueprints that represent hard-vetted ground truth.
A cornerstone of our approach at Kashikoi is building a world model around the business artifacts you already have. These are artifacts that a team of knowledge workers have settled upon through elaborate processes—PR review systems, contract negotiations, legal compliance. They represent consensus reality for your organization.
We start with these ground-truth artifacts and build a world model using our patent-pending technology. Our simulation engine then creates grounded, simulated users who can interview any AI system you plan to use or ship.
This grounding is what makes the difference between an LLM-as-Judge that agrees with itself 40% of the time and one that achieves 90%+ intra-annotator agreement.
A Real-World Case Study
This all sounds promising in theory. But what does it look like in practice, and why is this approach easier than alternatives?
We worked with a client who, in the interest of bringing rigor to their coding assistant development, collaborated with subject matter experts to handcraft an evaluation set. The golden set was constructed over a code repository: questions that potential users might ask the coding assistant, paired with hand-crafted golden answers that SMEs considered ideal responses.
This golden set was intended to become part of the CI/CD pipeline for the coding assistant. An LLM-as-Judge prompt would evaluate agent responses daily on this set to track performance.
The golden set took several weeks to construct. But development proceeded at a faster pace, so when the evaluation arrived in final form, the team barely had time to translate its results into actionable development tasks.
Then came the real problem. On running the evaluation multiple times, one issue became immediately clear to the devs and QA team: the LLM-as-Judge barely agreed with its own ratings from one run to another. Given the same agent response, the same golden answer, and the same evaluation prompt, the evaluation did not produce consistent ratings.
The evaluation was summarily relegated to a gatekeeping role, useful only for detecting major red flags, not for providing meaningful CI/CD feedback.
This sounds surprising, but it’s common. There’s a basic test that most LLM-as-Judge configurations fail: repeatability. Going back to the original scene, a fundamental requirement of any evaluation system is trust. This requires two dimensions: repeatability (reliability) and coverage.
Sometimes I’ve seen evaluation sets dumbed down to fit the need for repeatability: coverage gets sacrificed, metrics get simplified. But the overall suite still fails because it provides no meaningful signal downstream to developers and product owners.
Historically, trust in evaluations came from humans creating the source of verification. But with the pace of modern development, static evaluation sets are no longer dynamic enough to service a team’s needs.
How do you achieve both reliability and coverage? Our view at Kashikoi is that you can achieve both through a simulation-based approach grounded in business artifacts.
Quantifying the Problem
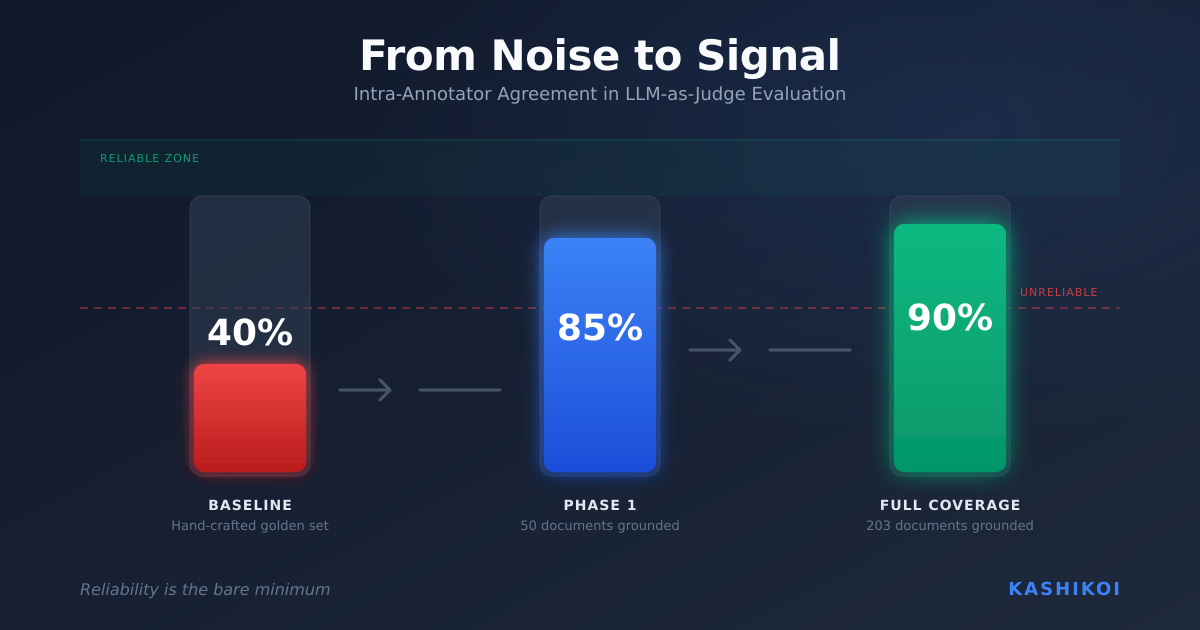
When we started working with this team, we first decided to quantify the probblem i.e. the lack of reliability in their golden evaluation set.
At the time, this carefully constructed golden set’s LLM-as-Judge setup had an intra-annotator agreement of 40% over an evaluation set covering only 25 markdown documents.
This was the root cause for why the entire evaluation effort had stalled, and ad-hoc testing or customer complaints had become the poor substitute for a functional CI/CD system.
We then worked with the team to re-establish trust by developing an evaluation set that improved both intra-annotator agreement and coverage—an evaluation set over which devs, QA, and PMs could have valid conversations that might actually move the needle.
Our first evaluation set was grounded in 50 raw documents from the codebase. The information required to verify any agent’s response was contained in those 50 documents.
After freezing the questions, we proved that our system achieved an intra-annotator agreement of 85%—more than doubling the reliability of the human-constructed set, without compromising coverage or metric complexity. We achieved this because our simulation system is backed by a world model grounded in the technical details of the codebase itself.
What We Learned
Some patterns emerged around what drove evaluation instability:
Extreme ratings are stable. Both the human golden set and our simulated evaluation showed high LLM-as-Judge agreement at the extremes. It’s easier to tell when an answer is great or wrong.
The middle is where instability lives. Answers rated as partially correct often flip to correct or wrong across runs. This middle ground is where most LLM-as-Judge setups lose their reliability.
Human golden answers are terse; LLM answers are verbose. The SME-written golden answers assumed the reader already understood the technical fundamentals. They were short and precise. LLM-generated answers, by contrast, often provided extensive context on the technical problem. Context that might feel like slop to an expert but comprehensive to a novice. The same answer could earn different ratings depending on unstated assumptions about the reader.
Grounding the rubric to intent matters. One key reason our evaluation system achieved higher reliability is that our world model approach grounded the evaluation rubric to the intent of every question. The LLM-as-Judge had access to raw ground truth and the world-model-driven detailed intent of the question i.e. a customized rubric mapping every sample’s intent to ratings. This context made the judgment more consistent.
None of this diminishes the role of subject matter expertise. However experts are most valuable when they focus on edge cases and the questions and scenarios where simulation reveals the agent is struggling. Or better yet: creating new documentation that captures the subtleties of technical contributions, which can serve as future context for all LLM based tasks like code generation, verification etc.
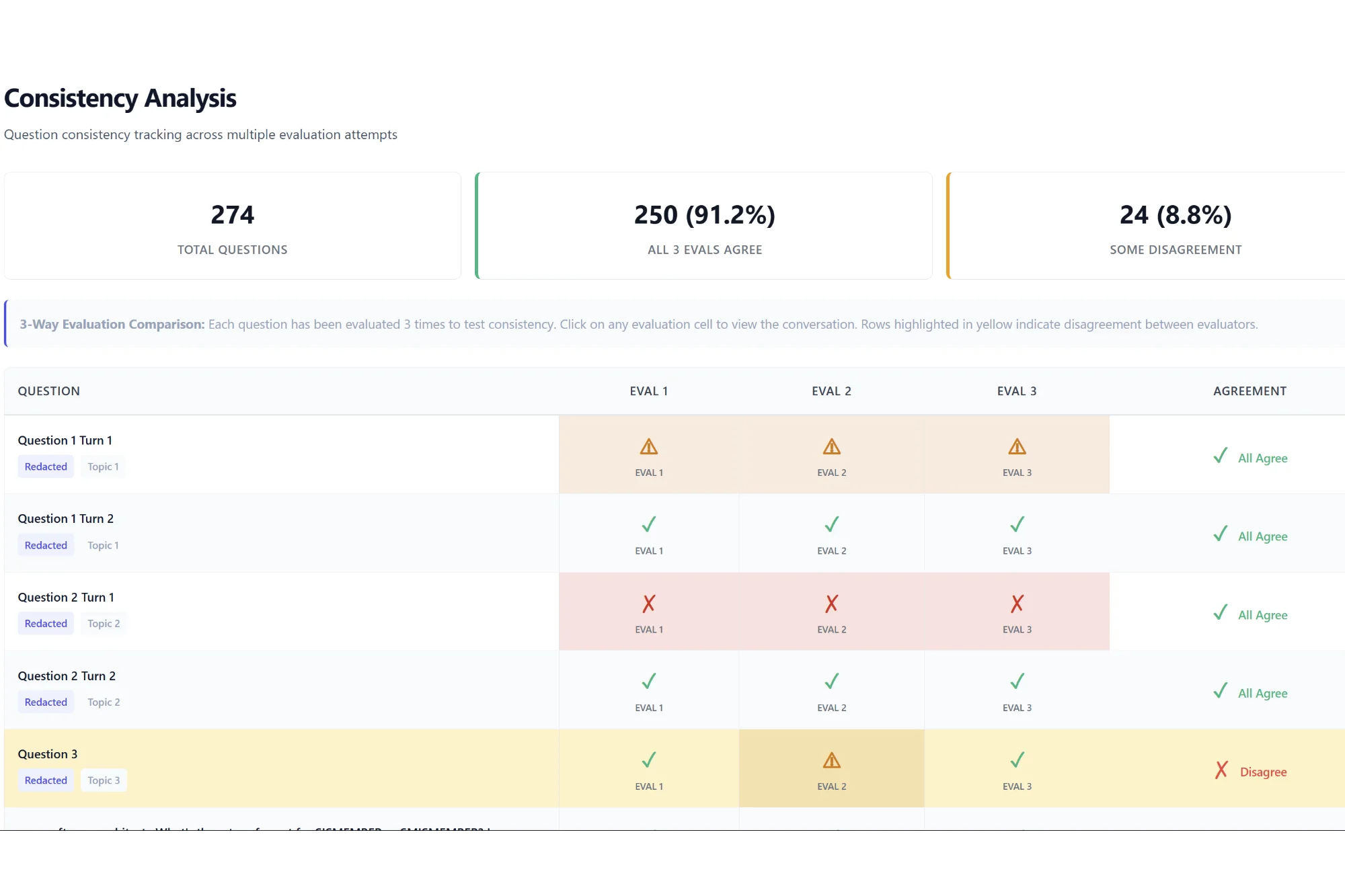
After this initial success, we expanded the evaluation set to cover all 203 documentation files in the target codebase, achieving 90% intra-annotator agreement across the full set with ~400 samples. A large enough sample size such that you have more than one sample to debug issues.
We even added a specificity metric, one that identifies answers that are technically accurate because they touch on general concepts but fail to highlight the nuances for which the target codebase was actually written. Because AI answers can be correct and still be slop.
A Simple Test You Can Run Today
Whether you reach out to us or not, here’s a simple test you should put any LLM-as-Judge prompt through:
Run it three times on the exact same underlying data. Load the results into a spreadsheet and count how many times the LLM-as-Judge agrees with itself across those three runs.
That number will tell you more about the future of your agent than a defensive developer, a struggling QA team, or a user who expects the world.
If you want an evaluation set that will actually keep you up at night for the right reasons, get in touch with Kashikoi. Contact us at founders [at] getkashikoi.com!

Leave a Reply