
Many have thought they’ve solved synthetic log generation with an LLM. They haven’t.
Synthetic logs are almost always garbage. Not obviously garbage, which would be fine (you’d catch it immediately). They’re subtly garbage. The kind that passes a quick glance but falls apart the moment a real security engineer or SOC analyst actually uses them. When you’re building AI agents that need to interact with realistic Okta environments, or detection rules that need to catch actual threats, “subtly garbage” destroys everything.
The real bar isn’t just generating logs that look like Okta logs. It’s creating simulated Okta logs that are as believable as real ones. That means modeling human behavior, not just data patterns. It means keeping user IDs, device fingerprints, and IP geolocations consistent across sequences of events. It means understanding that humans don’t log in from San Francisco at 2pm and Tokyo at 2:05pm, unless they’re a very dedicated frequent flyer or something deeply suspicious is happening.
After spending way too long on this, we finally figured it out. The key was switching from treating this as a data generation problem to treating it as a behavior simulation problem. What didn’t work, what finally did, and what we learned along the way.
The realism problem nobody talks about
Most synthetic data is optimized for looking right, not being right. This has been a known problem in the industry for years, but people keep making the same mistakes.
If you’ve ever worked with synthetic logs, you know what I’m talking about. They check all the obvious boxes: valid JSON structure, correct field names, plausible timestamps. Great! Ship it!
Then a SOC analyst opens them up and immediately knows something’s wrong. Perhaps the user agent strings don’t match the operating systems. Maybe someone’s logging in from an IP address in Texas while their geolocation says they’re in Oklahoma (commercial GeoIP databases have around 66% city-level accuracy and can be off by 50km+, but they’re 99.8% accurate at the country level, so cross-continental mix-ups basically never happen). Maybe the session IDs are changing mid-session, or the device fingerprints are too perfect, or a hundred other tiny details that scream “this was generated by something that doesn’t understand how Okta actually works.”
What makes Okta logs particularly brutal to simulate: everything is connected. Your IP address determines your geolocation, which should roughly match your timezone, which influences when you’re likely to log in, which affects what applications you access, which creates certain patterns in your session data. User agents aren’t random strings; they’re declarations of browser capabilities that must match the OS version, which must be compatible with certain device types. It’s a massive web of interdependencies.
For AI security companies building agents that interact with Okta, this realism isn’t optional. You can’t train an agent on fake data where users teleport between cities or where device fingerprints randomly change. The agent learns those patterns are normal, and then completely fails when encountering real Okta environments. Same for SOC analysts testing detection rules. If your test data doesn’t include realistic attack patterns (like actual credential stuffing timing or genuine brute force rhythms), your detection engineering falls apart at scale.
The technical term for what we needed is “deterministic field consistency.” Less technically: stop making up random values for every field and start understanding that fields have relationships. A lot of them.
Attempt 1: Just ask the LLM!(narrator: it did not work)
We started with LLMs. Have you seen what GPT-5 can do? It can write poetry, explain quantum mechanics, and debug recursive functions. Surely it can generate some Okta logs, right?
We gave it really detailed prompts with examples of real Okta logs and had it generate sequences of events for realistic user behaviors.
Attempt 1a: Basic prompting
First try: “Generate Okta system logs for a user named John Smith logging in from San Francisco and accessing Salesforce.”
Results: Hilariously bad. The logs looked great individually! Each one had all the right fields. But across a sequence? John’s user ID changed halfway through. His IP address was from a San Francisco range, but the geolocation said Miami! His device went from “Computer” to “Mobile” and back to “Computer” within the same session. Accuracy for generating a single believable log: maybe 20-40% if we’re generous.
Accuracy for generating a believable sequence of related logs: <5%. And that’s being generous.
Attempt 1b: Few-shot prompting with detailed examples
Maybe we just needed better prompts. We tried few-shot learning with meticulously constructed examples showing proper session flow, consistent user IDs, realistic timestamp gaps. We wrote prompts that could double as novellas, explaining every constraint.
The LLM got better, I’ll give it that. User IDs stayed consistent! But then we’d get user agent strings that were complete nonsense, like “Mozilla/5.0 (Windows NT 10.0; Mobile)” (Windows NT on a mobile device? Really?). Or timestamps that put events out of logical order. Or IP addresses that were technically valid but would never appear in an actual Okta deployment (IE: 127.0.0.1 for a “remote” login).
The fundamental problem
LLMs are really good at generating things that look right superficially. They understand patterns and can mimic structures. But they’re terrible at maintaining internal consistency across extended sequences. They don’t actually have a model of how Okta sessions work. They just know what Okta logs look like textually. It’s like the difference between memorizing the words to a song in a foreign language versus actually speaking the language.
GPT-5 doesn’t “know” that if user 00u1785fc892YN6Tb1d8 is using device abc123xyz from IP 208.223.254.2, those values need to stay consistent throughout the session. It generates each field somewhat independently, sometimes copying from context but often introducing small variations that cascade into complete nonsense.
What killed it: LLMs couldn’t consistently keep user names and device IDs straight across logs, let alone user agent strings. They’d generate a user agent like “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)” and then in the next log switch to “Mozilla/5.0 (Windows NT 10.0)” for the same device, in the same session. Face-palm moment #847.
We knew we needed a better approach.
The world model breakthrough (or: what actually worked)
At Kashikoi we have invested in building world models from Day 0. Just generating data is not going to work, you need to first model behavior. This insight is a common pattern in some of the most successful physical AI deployments in the world: RL-style environments for training agents.
There’s this distinction between AI being “textbook smart” versus “street smart”, between systems that can ace benchmarks versus systems that actually work in messy reality. Pure LLM generation was textbook smart. It knew what logs should look like. But it wasn’t street smart. It didn’t understand how humans actually behave. (As Surge AI puts it when building their RL training environments: they need to be “grounded in real worker experience.”)
Humans don’t generate random sequences of Okta events. They follow patterns, but not rigid, deterministic patterns. Someone logging in for work might:
- Check email immediately after authenticating
- Access Slack within 30 seconds
- Open Jira sometime in the next 5 minutes
- Take a coffee break (no activity for 15 minutes)
- Access GitHub when they start coding
- Gradually wind down activity toward end of day
Or they might do something completely different! Work from a coffee shop (new IP but same city). Forget their password and fail three login attempts before succeeding. Get locked out and need to reset via mobile. Travel internationally and trigger impossible-travel alerts.
These aren’t just random data points. They’re behavioral patterns. And behavioral patterns are exactly what our world models are designed to capture.
The architecture shift: We completely removed LLMs from the decision-making process. They’re not deciding what happens next. Instead:
- Multiple specialized world models handle specific sequence behaviors (login flows, access patterns, travel scenarios)
- The environment fills in all the deterministic fields and ensures consistency
- LLMs only get used for specific data generation tasks where they excel (like creating realistic display names or error messages)
The world model is the director of a play, making sure actors enter and exit at the right times and follow logical story arcs. The environment is the props department, making sure every coffee cup that appears on stage is consistent and physically plausible. The LLMs are character actors, occasionally improvising dialogue but within strict guardrails.
An example flow:
- World model decides: “User will attempt login from new device, fail once with wrong password, succeed on second attempt, then access an application”
- Environment generates: Consistent user ID, new device fingerprint, IP address with matching geolocation, realistic timestamp spacing
- World model controls: Which applications get accessed and when the MFA challenge occurs
- Environment validates: User agent matches device type and OS, IP geolocation is consistent, session IDs link related events correctly
The world models capture the variety of human behavior, not just one canonical flow. Humans accomplish the same goals (accessing applications) in many different ways, with different timing patterns, different sequences, different failure modes. Our models learned these different paths by observing real patterns.
Want to try it yourself? We’ve got a free version at oktalog.getkashikoi.com where you can generate simulated logs and see the difference.
The implementation uses multiple models because different behaviors have fundamentally different structures. A successful login-to-work sequence looks nothing like a brute force attack, which looks nothing like an impossible-travel scenario. Trying to cram all of that into one prompt just dilutes the quality of each.
The high-level insight is: model behavior, not data. Let the environment handle consistency. Use LLMs as tools, not decision-makers.
Making simulated Okta logs actually pass the sniff test
We had world models generating behavioral sequences and an environment ensuring field consistency, and thought we were done.
We were not done.
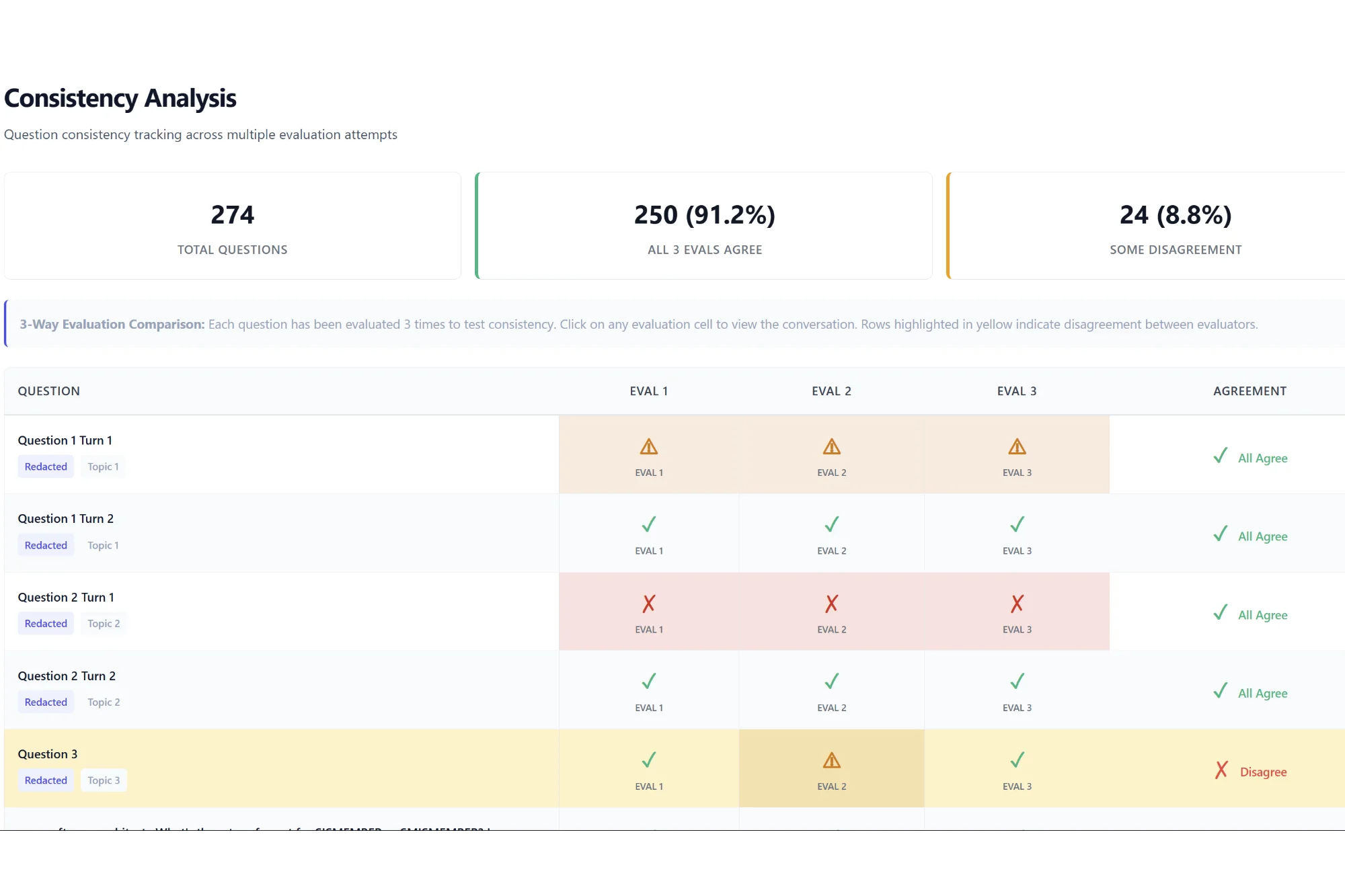
When we started showing our logs to SOC analysts, we discovered dozens of subtle issues we’d completely missed. It’s one thing to maintain consistency within our own system. It’s another to match all the weird edge cases and quirks of real Okta environments.
What surprised us most was how much environment validation mattered. We’d obsessed over behavioral realism (and we still do, it’s critical). But there’s a whole other layer of realism in the environmental details:
IP geolocation matching turned out to be weirdly hard. Commercial GeoIP databases like MaxMind are only ~66% accurate at the city level. Real Okta logs reflect that imperfect accuracy! Sometimes an IP in San Jose shows up as Santa Clara, or vice versa. If your simulated data has perfect IP-to-city matching, it’s actually less realistic than real data. We had to intentionally introduce the same kinds of geolocation variance that exists in production.
Behavioral realism checks evolved too. Early versions modeled “travel” as just changing the IP geolocation. But real travel has patterns:
- Local travel: Drive 20 miles, IP changes, still same metro area
- Regional travel: Fly to another state, time zone changes, login patterns shift to new local time
- International travel: Major timezone shift, possible VPN usage, device might change (hotel wifi vs mobile), longer session gaps
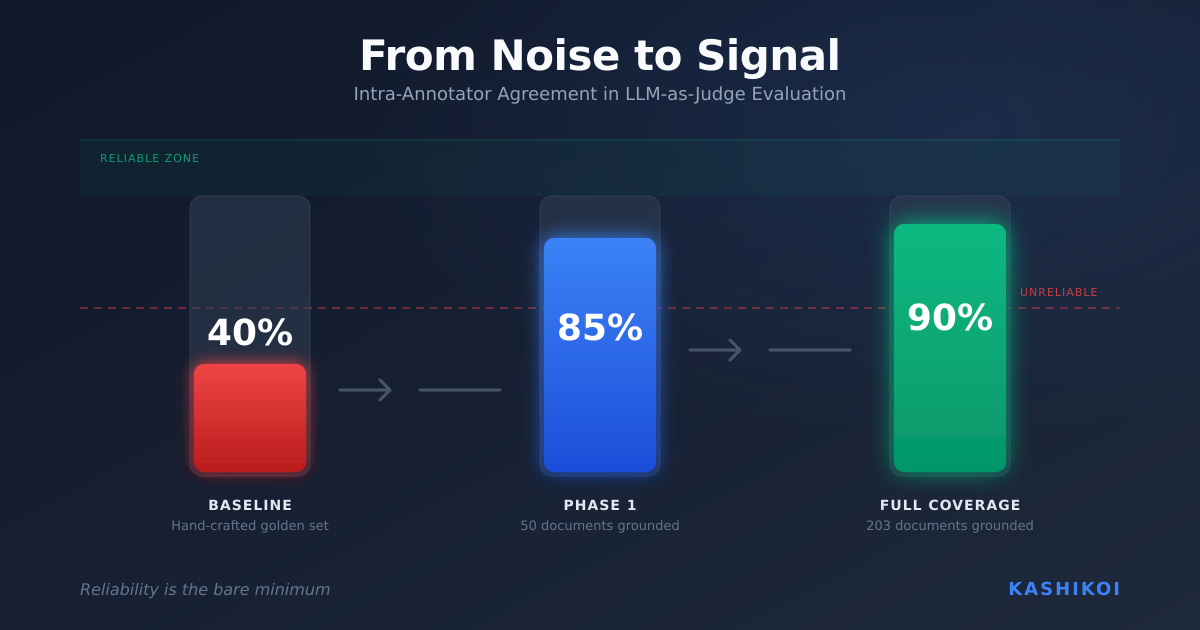
Current state: Our simulated logs have consistently been validated by SOC analysts in blind tests. We’re at 85-90% realism for most common scenarios. The remaining 10-15% is the long tail: edge cases, rare event combinations, subtle quirks of specific Okta configurations.
Getting to 70% quality is relatively fast. But every additional 10% beyond that? It takes exponentially longer. We’re living that reality. Those last percentage points require discovering and fixing dozens of small issues that only appear in specific circumstances.
Where it goes next: Multiple log types with cross-log relationships. Right now we do Okta really well. But real environments have Okta logs, AWS CloudTrail logs, application logs, network traffic logs, all of which are related. An authentication event in Okta should correlate with API calls in AWS, which should align with application access logs. That’s the next frontier.
Beyond security, this approach applies to any system where you need to simulate realistic behavior for testing. Support ticket systems. E-commerce platforms. Healthcare records. Anywhere that pure synthetic data falls short because it doesn’t capture how humans actually interact with systems over time.
Ready to test your security agents against realistic scenarios? Start generating Okta logs for free at oktalog.getkashikoi.com – no credit card required.
Want to influence what we build next? Vote on our roadmap: should we prioritize malicious behaviors, benign edge cases, or system errors? Cast your vote here (no signup required).

Leave a Reply