
Three things have happened in mathematics this past year. Same technology. Three very different outcomes. And a pattern that we at Kashikoi think enterprises should watch closely.
Three Proofs, Three Outcomes
The First Proof Challenge
Earlier past year, 11 top mathematicians put 10 mathematical research-level problems in front of leading AI models. The AIs produced confident proofs for every single one. Only 2 were correct.
The rest was what Ken Ono called “proof by intimidation”. The AI said everything with such authority that even experts hesitated to push back. Terence Tao warned that AI has broken a signal that held for centuries. Historically, subpar mathematicians were also subpar mathematical writers. The quality of the argument tracked the quality of the reasoning. Now the writing is flawless whether or not the reasoning is sound.
This is a fairly obvious failure mode. The AI is wrong, but it sounds right.
This is not without human precedent however (in that errors have been discovered in popular human proofs too). Naturally the scientific community has invested in formal verification systems like Lean.
Math Inc.’s Gauss
Earlier this month, Math Inc’s AI agent auto-formalized Viazovska’s Fields Medal-winning sphere-packing proof. First the 8-dimensional case in five days, then the 24-dimensional case in two weeks. The 24D proof alone is over 200,000 lines of Lean code. It’s formally verified because the Lean compiler checks every step. Technically, this is correct.
But no human can read it. No individual mathematician can follow the full chain of reasoning from start to finish. The proof is verified by a machine, about work done by a machine, producing output no human can independently audit. The mathematicians set the blueprint and the overall structure. However once Gauss took over, it filled in the gaps at a speed and scale that put the details beyond human comprehension.
Notably, the formal verification community was already contemplating the utility of proofs that no human understands after the First Proof Challenge. Lo and behold – just months later we have Math Inc’s Gauss.
“The four-color theorem was proved with a computer,” Buzzard noted. “People were very upset about that. But now it’s just accepted. It’s in textbooks.”
Computer assisted proofs are not a new phenomenon. However, they are harder to build upon or use for any further mathematical discovery (and so far an edge case).
Donald Knuth’s “Claude’s Cycles”
The 87-year-old godfather of computer science published a paper describing how Claude Opus 4.6 solved an open graph theory conjecture he’d worked on for decades: the decomposition of directed graphs into Hamiltonian cycles for all odd dimensions. 31 guided explorations. About an hour. He opened the paper with “Shock! Shock!” and closed with “It seems I’ll have to revise my opinions about generative AI.”
The detail that matters most is that though Claude found the construction, Knuth wrote the proof.
The AI explored a vast solution space by trying linear formulas, brute-force search, geometric frameworks, simulated annealing etc. The human took the result and verified it through traditional mathematical reasoning. Claude’s bad explorations cost nothing. Just wasted steps. The one good exploration was transformative.
This paragraph in solving the conjecture is noteworthy:

This kind of insight and guidance that eventually led to the solution and proof is important. From the superset of 11502 cycles, 4554 solutions formed the target subset. 996 had some generalizable cycles and 760 of those consisted entirely of generalizable cycles. To get the AI to focus on these needed expert guidance.
Not only that, it takes an expert to also check for the qualitative nature of the solutions. “Are they nice?”, paraphrase for do they have more structure and symmetry that can be explored further for a neater theory? Do they pass the “smell test”? The mathematical “taste” test?

The Verification Spectrum
First Proof: AI is wrong, but sounds right. Humans have to look very closely because confidence is indistinguishable from correctness. Naturally, formal verification systems like Lean are gaining traction.
Math Inc.: AI is right, and mechanically verified (via Lean) but the output is too vast and complex for any human to independently follow or audit.
Knuth: AI finds the answer, human verifies independently. Both work collaboratively and the contributions truly move the needle.
There’s a concept from probability theory that explains why the difference between these three matters far more than most people realize and why it’s the most important idea in AI risk that almost nobody in the industry is talking about.
Ergodicity: The Concept the AI Industry Needs to Internalize
A system is ergodic when the average outcome across many parallel runs equals the outcome for one run over time. One person flipping a coin 1,000 times sees the same distribution as 1,000 people flipping once. The time average and the ensemble average converge.
A system is Non-Ergodic when they diverge.
The classic example: 100 people play a game where each round they gain 50% or lose 40%. The average across all players looks great, positive expected value every round. An analyst looking at the group says “this game is wonderful.”
But follow one player over time and they get ground to zero. The multiplicative losses compound. One bad streak and you can’t recover because you’re multiplying from a smaller base each time.
The ensemble average says “play.” The time average says “you’ll go broke.”
The key ingredient is irreversibility. Any system where a sufficiently bad outcome removes you from the game permanently or changes the trajectory in ways you can’t undo is non-ergodic.
Wealth. Health. Reputation. You don’t get to live 1,000 parallel lives and take the average. You walk one path, and a wipeout at step 50 means there is no step 51.
This reframes risk management from a boring compliance exercise into the core discipline. The first priority is always: stay in the game.
What Ergodicity Predicts About the Three Proofs
Now map this back onto the three math events.
The Knuth workflow is roughly ergodic.

Claude explores, proposes, fails, tries again. Bad outputs are additive, they waste time but in this case the human guidance prevents them from becoming irreversible dead ends.

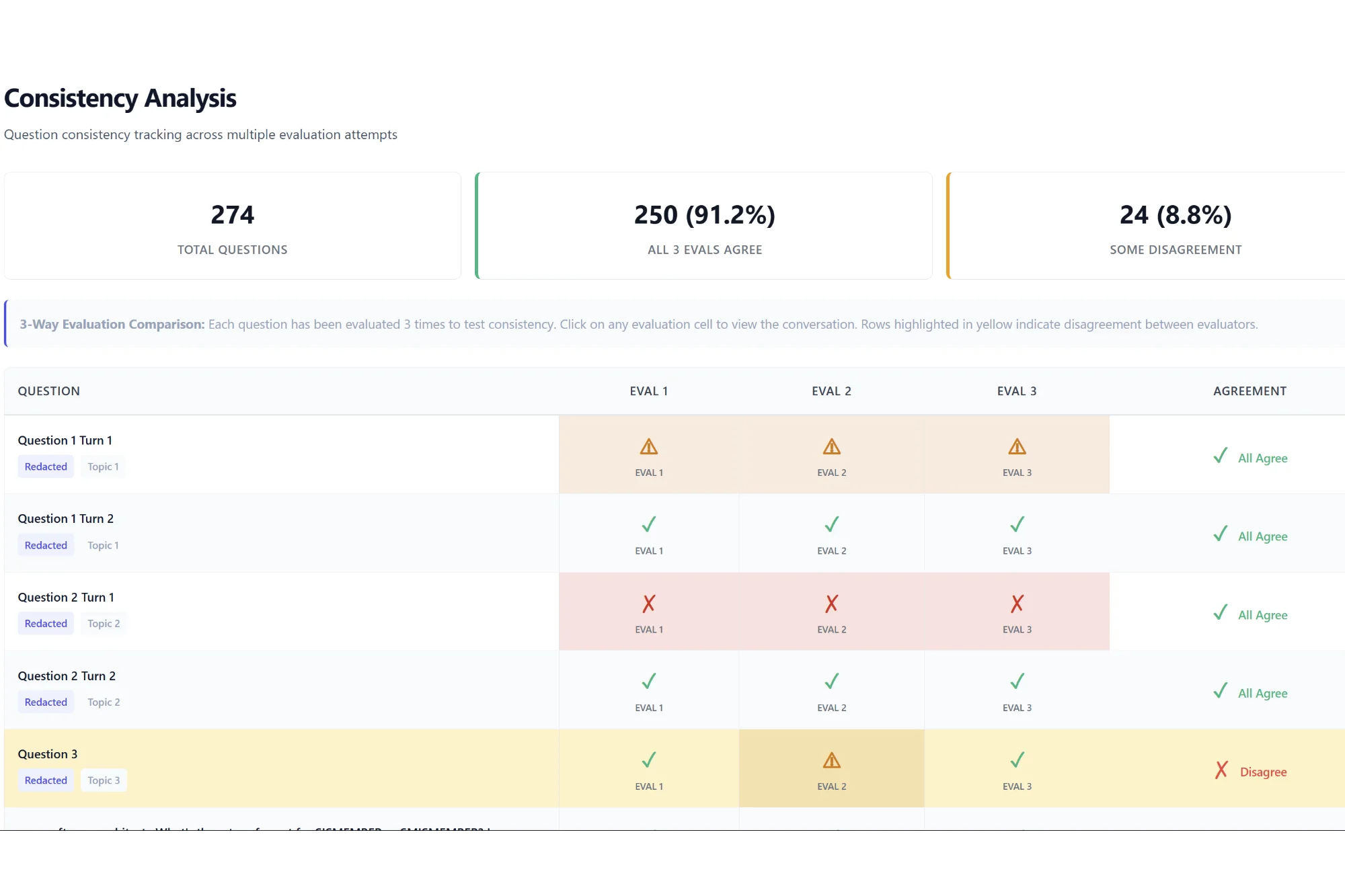
Independent evaluation was an integral part of the workflow. The cost of 30 bad explorations was trivial. The value of the 1 good one was enormous. All of this was because the process did not allow any single failure to become irreversible.
The First Proof workflow is at the risk of being non-ergodic. If you accept a wrong proof, downstream theorems get built on a false foundation. Other researchers cite it. Techniques get developed from it. The damage cascades and you may not discover the error for years. A single accepted-but-wrong proof corrupts everything that depends on it. Moreover, the AI’s confidence tried its best to make the human checkpoint ceremonial in this case.
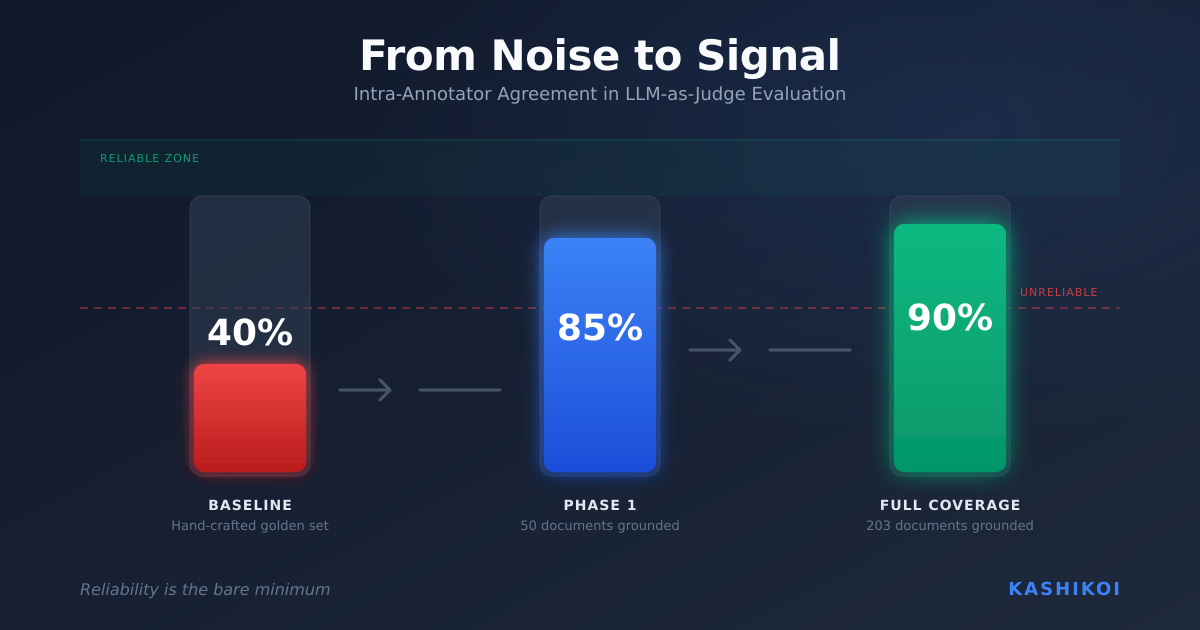
At the very least, the takeaway from the First Proof experiment is that using AI in autonomous modes has to be coupled with autonomous verification tooling as well.
The Math Inc. workflow succeeded but points toward a non-ergodic future. In this case, the proof is correct. The compiler verified it. The mathematicians provided the blueprint. The system worked. But consider what this workflow looks like as it scales: verification moves from humans to machines entirely. The checkpoint isn’t ceremonial because the human rubber-stamped it. It’s ceremonial because the human was never in a position to stamp it at all.
The insidious failure mode here is that the solution is still largely unaligned with the goals of mathematical research, one of producing insights, theorems and axioms that future research can build upon.
The moment verification becomes ceremonial, you’ve silently converted an Ergodic system into a Non-Ergodic one.
Real Checkpoints vs. Ceremonial Checkpoints
Every agentic workflow sits somewhere on the ergodic spectrum. And that position depends entirely on one question: Is your checkpointing system real or ceremonial?
The obvious cases are straightforward:
Code suggestions with human review → bad output wastes time → Ergodic.
Code agent with deploy access → bad output takes down production → Non-ergodic.
Summarization agent → Ergodic.
Customer-facing agent sending emails autonomously → Non-ergodic.
Security alert triage report→ Ergodic.
Agent that auto-modifies access permissions → Non-ergodic.
The common thread: any workflow where the agent directly writes to a system of record is non-ergodic.
Wherever the cost of bad output is additive (wasted time) rather than multiplicative (ruin, irreversible dead end), the workflow is ergodic otherwise its non-ergodic.
The Enterprise Parallels
The First Proof failure mode: AI is wrong but sounds right.
In the enterprise, this is the AI-generated risk assessment that reads like it was written by a senior analyst. The strategic recommendation that’s articulate, well-structured, and confidently wrong. The sales forecast that pattern-matches to what leadership expects to hear. The human reviewer sees polished output and approves it not because they verified the reasoning, but because the presentation quality signaled competence.
Confidence overwhelms judgment. The checkpoint becomes ceremonial.
The Math Inc. trajectory: AI is right, but humans can’t independently verify.
The risk model that passed QA because the QA process couldn’t meaningfully interrogate it. The multiple-page regulatory filing assembled by an AI where the reviewer spot-checked the executive summary and signed off.
Complexity exceeds comprehension. The checkpoint becomes ceremonial.
Both paths lead to the same place: non-ergodic territory. Where the ensemble statistics still look great. However, your customer doesn’t live in the ensemble. They live on one path.
The Most Expensive Category Error in Enterprise AI
The subtle danger is the checkpoints that technically still exist but no longer function — the reviewer who can’t keep up with the volume, the approver who doesn’t have the context to evaluate what they’re approving, the QA process that was designed for human-generated output and can’t interrogate AI-generated output.
The “ship it and monitor” philosophy assumes mistakes will average out. That you can always course-correct. That’s ergodic thinking applied to a non-ergodic system.
So what does good look like?
As AI capabilities grow, there will be more and more workflows where human verification isn’t feasible. Where the output is too complex, too fast, or too voluminous. Where the Math Inc. pattern, an AI operating beyond human comprehension is the default, not the exception.
That’s where simulation and evaluation infrastructure come in. It’s what makes the checkpoints real when humans can’t be. Practically:
- If you want to leverage AI in autonomous modes, it has to be paired with an autonomous Verification System.
- A complete and scalable Verification System has to have all 3 components:
- Simulator(s)
- To explore the Non-Ergodic space as exhaustively as possible.
- Ideally backed by a World Model.
- Deterministic Verifier(s)
- E.g. Compilers, Fact Checkers, Unit Tests
- Alignment/Style Checkers (LLM-as-Judge)
- Simulator(s)

At Kashikoi, we not only provide all 3 but we first build a World Model for you that makes it easy to design and maintain the Verification System as a whole.
You can’t average your way out of ruin. You have to simulate your way around it!
If this resonates with you and you need a free 30 min. consultation to figure out where you are on the ergodicity spectrum, contact us at founders [at] getkashikoi.com!
Leave a Reply