The future survivors of the AI race will have made one critical mindset shift: they will have fully embraced the non-determinism of LLMs. They’ll stop treating LLMs like deterministic software and start treating them like probabilistic systems with risk profiles.
When it comes to talking about AI productivity, performance etc. people want single numbers. However we need to think in ranges : ceilings and floors, probabilities and risk.
The Determinism Hangover
Most software engineers (and most enterprise processes) are trained on a deep assumption:
Given the same input, the system should produce the same output.
Agents break that assumption. Structurally.
So teams sometimes do one of two things:
Trap #1: “We’ll deploy when it’s correct 100% of the time.”
This feels responsible but it is the comfort zone speaking. It’s also a great way to miss the adoption curve.
If your agent is genuinely useful 60% of the time today, “waiting for 100%” often means denying users that 60% value now. Besides some upstart will build that 60% solution, win early customers, iterate to 80%, and capture the market while this group sits in fairytale land demanding perfection.
Trap #2: “Who cares, models keep improving. We’ll just switch to the next model.”
This is worse, because it replaces rigor with vibes.
You ship without knowing:
- what your success rate actually is,
- what kinds of failures are happening,
- whether upgrades make you better or quietly break you.
The outcome is the same for both traps: you don’t develop a risk discipline. And agentic software is nothing but risk discipline.
Enter Alpha and Beta
There’s an industry that has made its existence answering these exact questions, living in the fuzzy zone of probabilities as a way of life. Finance. And it has a clean vocabulary for separating two things people constantly confuse:
- “How much of my outcome is just the market?”
- “How much did I uniquely contribute?”
That’s beta and alpha.
What is Beta?
Beta is the systematic risk of an asset. Simply put: how much your boat rises and falls with the big ocean waves.
- β = 1.0 → moves one-for-one with the market
- β > 1.0 → amplifies market ups and downs
- β < 1.0 → dampens them
Think:
- A dinghy that bobs exactly with each wave → β ≈ 1
- A speedboat that bounces harder than the waves → β > 1
- A cargo ship that barely moves → β < 1
For AI systems, beta measures how well your system tracks improvements in underlying LLMs. It is what you get by being exposed to the LLM wave.
And here’s the part many teams miss:
Maintaining β ≈ 1 is not automatic.
Every new model update requires prompt and context engineering to bring your system back to β = 1.0, to ensure your AI workflow moves in lockstep with the new LLM reality.
The first test of any prompt engineering is that it doesn’t degrade beta. This requires evals.
When customers demand you switch to a new model overnight, in their minds they’re asking for what’s rightfully theirs: systems that at least deliver market return. Otherwise, what’s the point?
It takes significant effort just to maintain β = 1.0. (*Read this real life account of Replit’s engineering team).
What about Guardrails?
LLM guardrails are designed to dampen the impact of LLMs, controlling outputs so they don’t veer in undesirable directions. You’re safeguarding against the downs.
This is pushing beta below 1.0. Protection against downsides works both ways i.e. against upsides too. Lower beta usually means fewer catastrophic failures and also fewer “wild” upside moments where the agent surprises you with something brilliant.
Leadership’s Job
Deciding the beta that makes sense for your business and environment is the sole role of leadership given factors like regulated vs unregulated workflows, reversible vs irreversible actions, cheap vs expensive failures, high trust vs low trust users, internal tools vs customer-facing automation.
I’d argue further: it’s actually leadership’s job to figure out how to operate at β ≥ 1.0 in the AI wave. There’s no point otherwise. To bet on β > 1 is to prepare to brave the downs that come with it.
Conversely, this is what lack of leadership would look like:
- Hanging out in Trap #1 or Trap #2 described above.
- No plans of figuring out the beta, (SEP).
- Create pressure while ignoring that trade-offs exist at every risk level i.e. demanding returns without understanding the risk budget
What is Alpha?
Alpha is the return above or below what beta alone predicts. Often called “excess return” or “manager skill.”
Simply put: the extra distance you cover because the captain makes smart moves, like catching a shortcut current the other boats missed. Two boats on the same wave can end up in different spots. That gap is α.
- α > 0 → outperformance
- α < 0 → underperformance
It comes from things you uniquely bring: proprietary data and context that actually matters, domain-specific toolchains, workflow design (especially fallback design), product UX that constrains ambiguity, orchestration and routing, memory and personalization and most importantly : evaluation discipline.
If beta is “the tide,” alpha is “the engineering + product skill that converts tide into outcomes.”
A Practical Playbook: Use Alpha/Beta to Ship Agents
Get the step-by-step practical playbook here!
The AI Defeatism Problem
In safe-space, off-the-record conversations, I keep encountering a particular strain of AI defeatism. This fear has been showing up more publicly as articulated in recent WSJ reporting on the tech world’s anxiety that AI may compress opportunity and reshape who gets to win economically. Another way of summarizing this fear is that since LLMs are absorbing alpha from the market so fast, it will all become beta one day. There will be no alpha left in white-collar jobs.
Kashikoi’s view: this is exactly why you need alpha/beta clarity.
“Everything becomes beta” is often what it feels like when you don’t have the instrumentation to see where your alpha still lives. This is why we at Kashikoi believe so strongly in fixing that gap.
Where Kashikoi Fits
At Kashikoi, we’re building a patent-pending simulation and evaluation system for agentic workflows.
If you can’t measure:
- you can’t budget risk,
- you can’t maintain beta through upgrades,
- you can’t prove alpha to customers,
- and you can’t scale trust.
What we focus on (in plain terms):
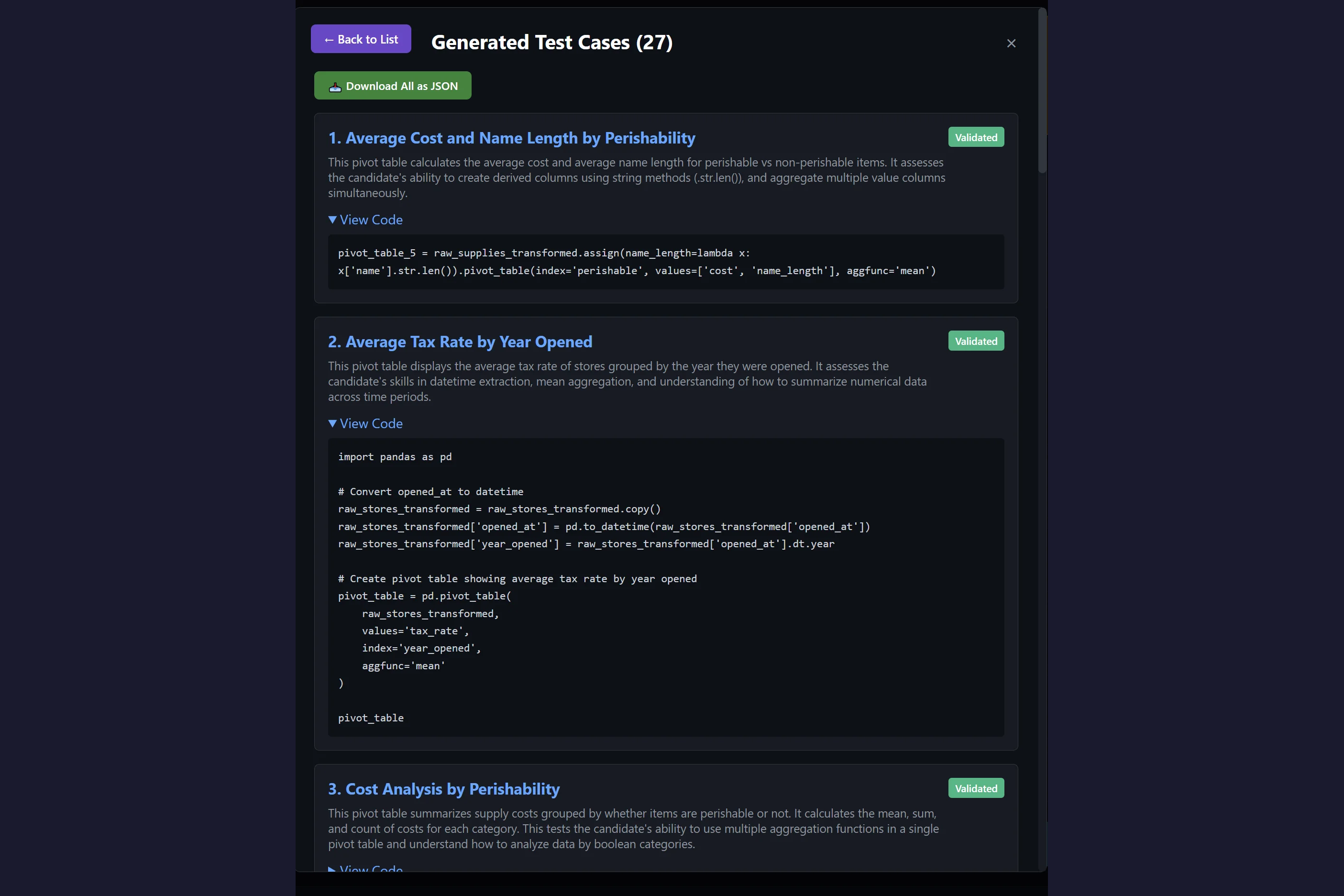
- evaluating agents in realistic simulations (not just public benchmarks),
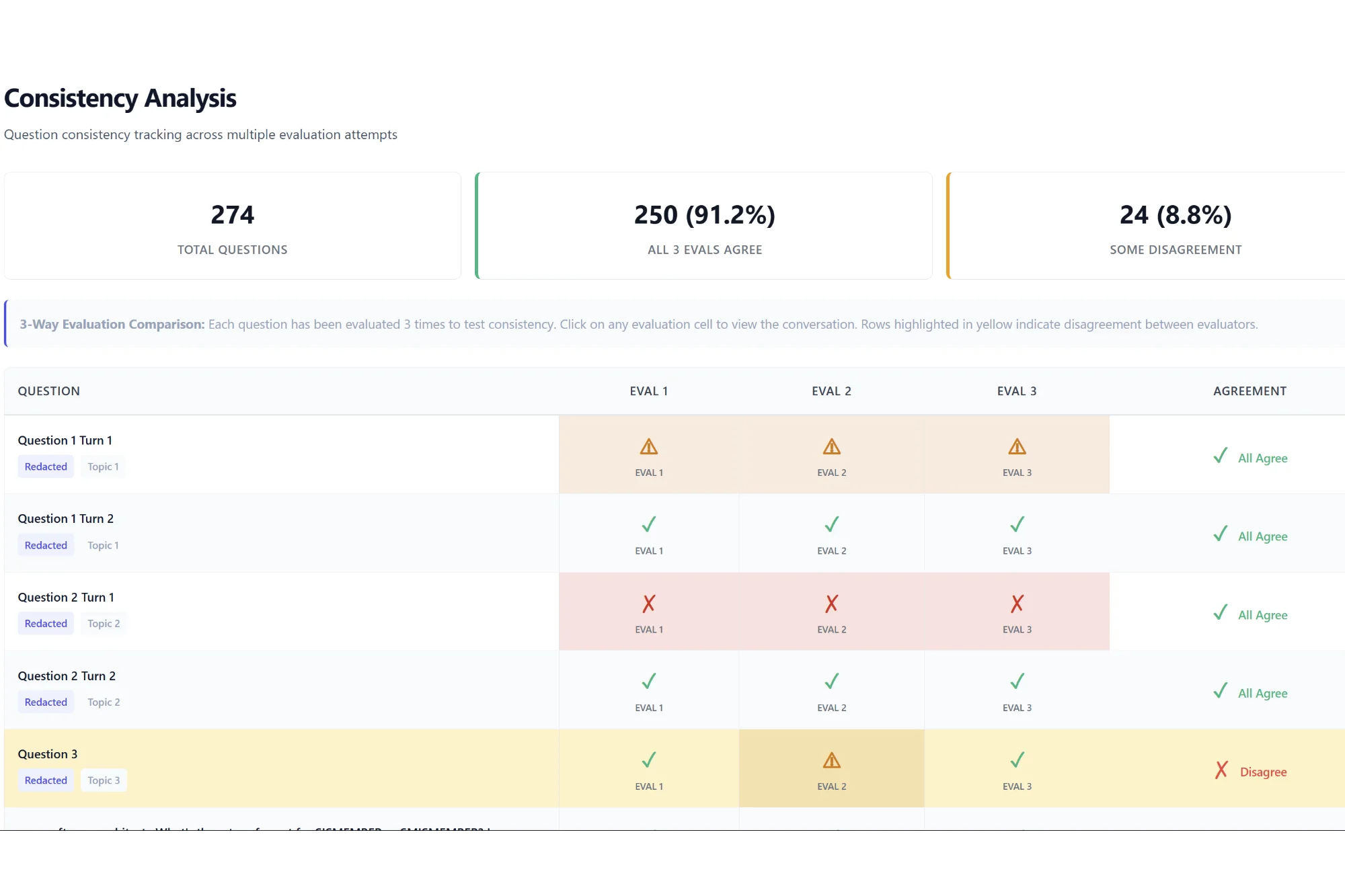
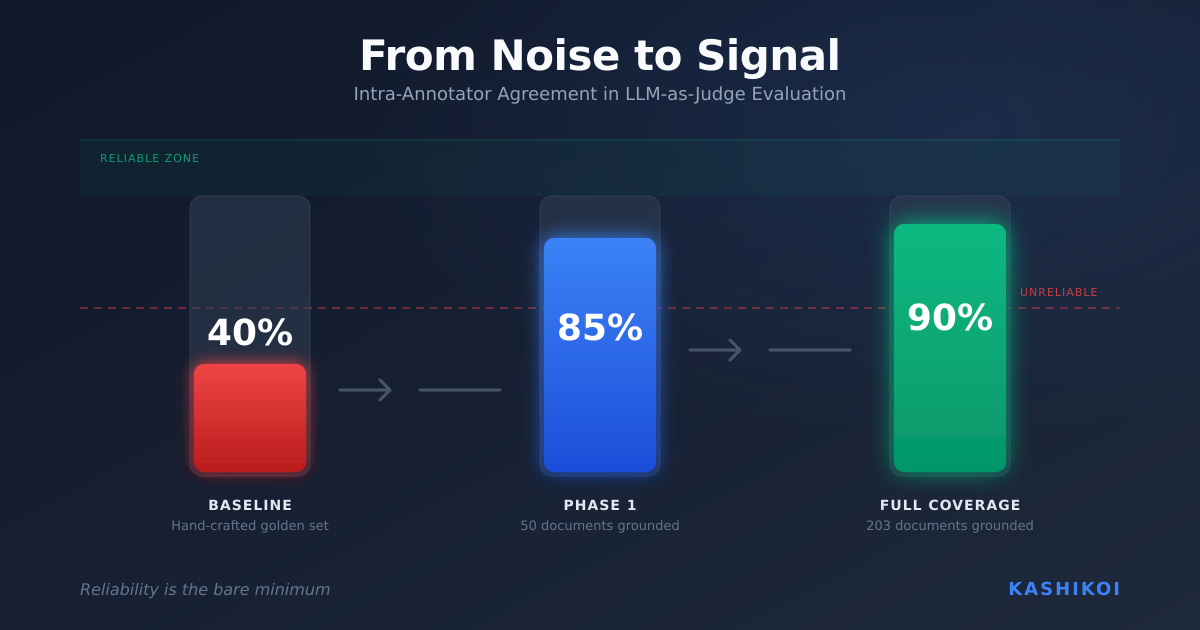
- evaluating the evaluator (how much should you trust an LLM-as-judge, and when?),
- and shipping updates with systematic reliability measures so downstream teams aren’t forced to “trust the test” blindly.
The survivors of the AI race won’t be those who demanded perfection or those who flew blind. They’ll be the ones who understood their beta, cultivated their alpha, and built the instrumentation to tell the difference.
If you’re building AI systems and want to understand where your alpha truly lies, contact us at founders [at] getkashikoi.com .

Leave a Reply